
I share half of my soul with them, and they share half of their songs with me.
By ilem
One day in the early 1890s, English songwriter Harry Dacre made his first trip to the United States. When he was entering the country, he was charged an import duty on the bicycle he was carrying. His friend William Jerome heard about it and quipped, “It’s lucky you didn’t bring a bicycle built for two, otherwise you’d have to pay double duty”. Dacre was so taken with the phrase “bicycle built for two” that he soon used it in a song. The song “Daisy bell” was recorded and released in 1893.
In 1961, researchers at Bell Labs were working on speech synthesis using the IBM 7094 supercomputer when they decided to try their hand at synthesizing songs. John Kelly and Carol Lockbaum handled the vocal generation part and Max Mathews did the backing track generation. They chose “Daisy Bell”, a well known love song at the time. Therefore, Daisy Bell became the first song in the world to be sung by computer synthesized vocals.
In this section, we will be discussing about Singing Voice Synthesis (SVS) technology.
Source-filter model
In 1942, Chiba and Kajiyama published their research on vowel acoustics and the vocal tract in their book, The Vowel: Its nature and structure. In this book, for the first time, they introduce a source-filter model to explain how humans speak.
The source-filter model considers the human phonatory system as consisting of two separate parts. The vocal folds vibrate is the source that produce impulse signals. The signals then passes through a filter system consisting of the vocal tract, throat, mouth, nasal cavity, teeth and lips.

The source determines the frequency of the sound signal. During speech, the lungs squeeze out air to produce airflow. When the vocal folds contract, the airflow impulse impacts the vocal folds and produces regular vibrations, emitting periodic airflow pulses. The regular pulses from the vocal folds are “oblique triangular waves” with the following time and frequency domain diagram.
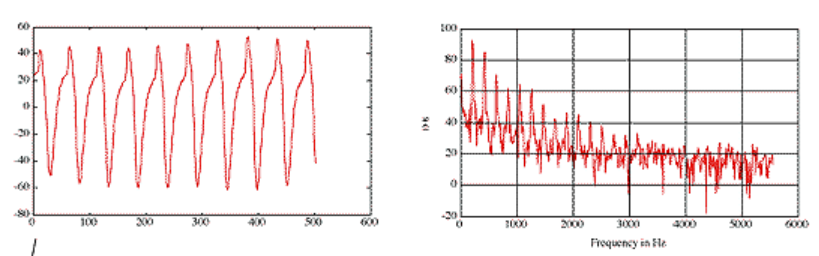
The approximated mathematical expression for a single pulse is:

Where $N_1$ is the rise time and $N_2$ is the fall time.
The frequency of the pulse is the base frequency of the human voice. The physical properties and tension control of the vocal folds determine the frequency of the source. The base frequency determines the pitch of a person’s speech and the range of their singing. When the singing pitch exceeds the range, the vocal folds will over-contract to produce high frequency vibrations. This vibration is usually weak. It relies on the resonance in the head cavity to amplify, which is also known as falsetto. When the vocal cords are relaxed, the high-speed flow of air creates turbulence and creates random white noise.
The properties of the filter determine the spectrum of the voice, and the spectrum determines the timbre and the content of the voice. The filter system attenuates and enhances the different frequencies in the pulse. There are many high-energy areas on the spectrum. They are the formants of the vocal.
In 2016, Professor Joe Wolfe from the University of New South Wales conducted an experiment to simulate the source-filter model. The experiment used a loudspeaker to simulate the source and 3D printed resonant cavities to simulate the filter system of human body. He tried to create the sound “Had” and “Heard“ with different resonant chambers.

The “HAD” and “HEARD” resonant cavities have different shapes and different transpedance for different frequencies, but both have several peaks (R1, R2, R3, etc.). As a result, several frequency peaks (F1, F2, F3, etc.) appear on the spectra after the impulse passes through the filter.
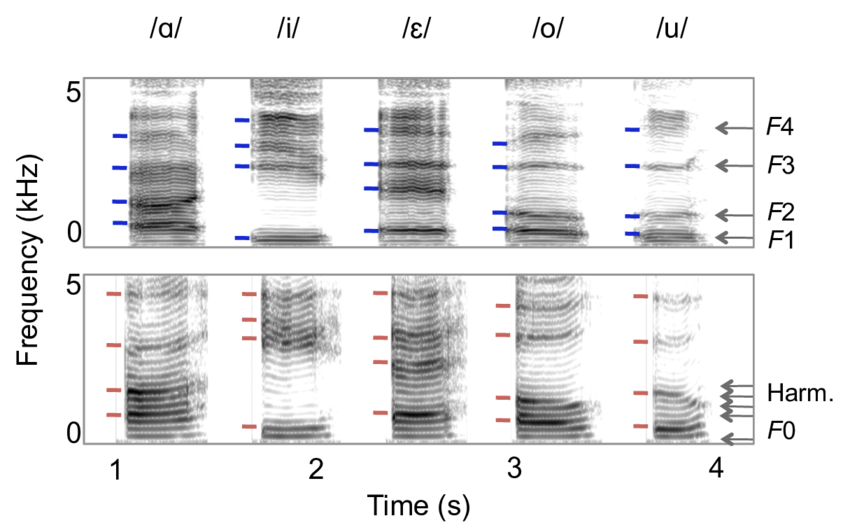
Below are some spectrograms of English vowels. You can see that each vowel has its corresponding formants.
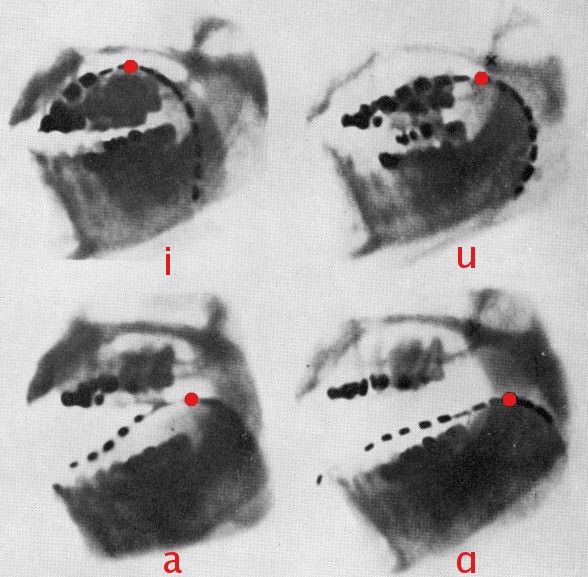
This is an x-ray of a person pronouncing different vowels, with the red dots representing tongue position. The difference in tongue position makes the acoustic properties of the human resonance cavity different.
By connecting these phonemes in a certain rhythm and frequency pattern, we have the singing voice. Theoretically, once we know the spectral characteristics and base frequency of each tone, we can generate the waveform by inverse transforms.
The public information mentioned here includes relevant patents, relevant research papers, etc.
Waveform concatenate
The spectra of most vowels are fixed, but language contains much more than vowels. When a person speaks and sings, each word contains several vowels and consonants. The shape of the resonant cavity changes constantly with the shape of the vocal tract, the opening and closing of the lips, and the position of the tongue, so the frequency response of the resonant cavity changes as well. The spectra are therefore dynamic and make the processing much harder.
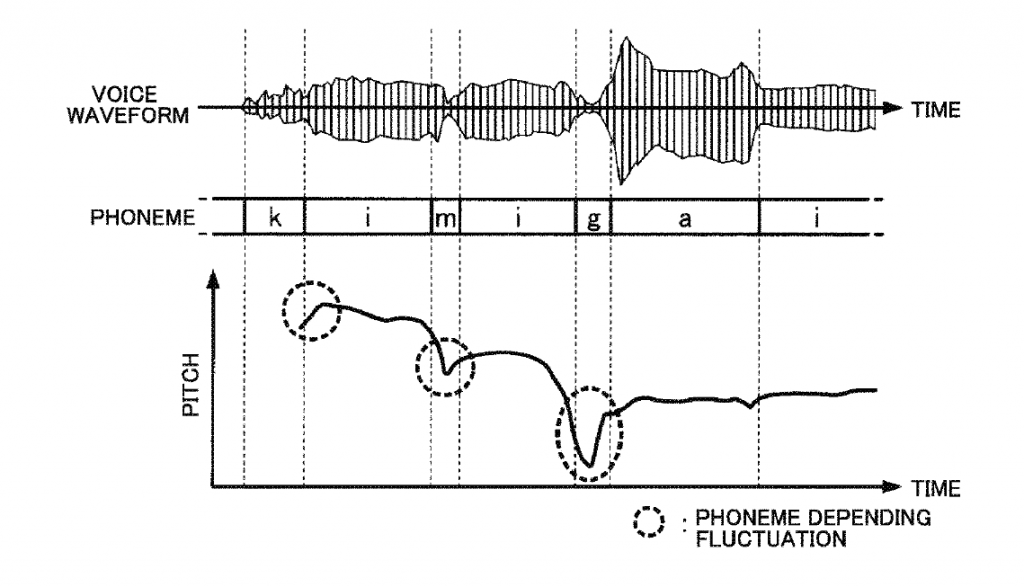
In addition, in real speech, there are small variations in the base frequency at the location of the phoneme articulation. This phenomenon is called “Phoneme Depending Fluctuation” in Yamaha’s vocal synthesis patent, as shown in the figure.
With these factors in mind, source-filter-based vocal synthesis requires complex algorithms and high processor performance, otherwise it sounds quite fake. Therefore, early synthesis software has adopted a “cleaver” solution: waveform concatenate.
In brief, waveform concatenate recordeds samples of various elementary phonemes. During synthesis, the software lifts these samples to the desired pitch.
Most speech synthesis software uses the International Phonetic Alphabet (IPA) to notate pronunciations. The original IPA contains a large number of special symbols, so computer mostly use ASCII-based notations of IPA such as X-SAMPA.
The most well-known waveform concatenation voice synthesis software is probably Yamaha’s VOCALOID. The .ddb library file of VOCALOID 4 contains a series of pre-recorded samples of vowels, consonants, and articulations between them.

The total number of samples is about 7600. The reason for this large number is that the waveform concatenation algorithm has difficulty handling the articulations between tones, it can only record every articulations enumeratively. Here are some sample examples. For example, the /a/ in IPA, which is the vowel a in modern Mandarin, and the articulation of /ən / to /i̯ou̯/ (noted as @_n and i@U in X-SAMPA), which is the articulation of en to you in Pinyin.
Considering the timbre changes when singing different notes, each phoneme in the library was recorded in three copies at three pitches. Unfortunately, due to the restrictions of the EULA, I can’ t show any sample examples here. If you are curious, you can go listen to them yourself.
When concatenating the voice, the editor automatically selects the required phonemes from the voice bank and puts them together. Here is an example of the song The original “Oath” by ilem, and the phonetic symbols for “你是信的开头” are n i si s\ i_n t 7 k_h al @U as shown in the Pinyin – Phonetic Symbols table on page 168 of the VOCALOID user manual.

Let’s try to find the corresponding samples and put them together manually:
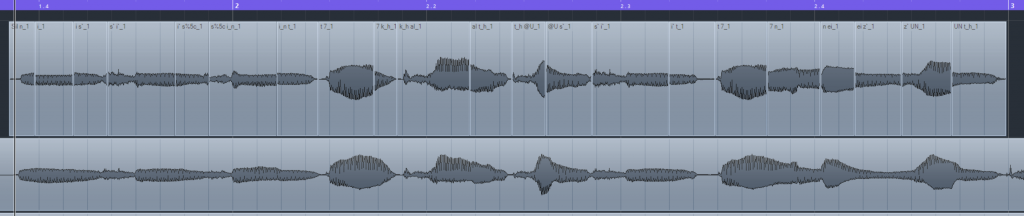
You’ll be able to hear the complete sentence. The phase misalignment during manual splicing causes a small amount of popping in the audio.
The waveform concatenation method has better timbre retention and lower performance requirements, but it also has obvious drawbacks. The waveform splicing method requires recording a large number (thousands) of sound samples and manually labeling them when creating a sound library, which is time-consuming and labor-intensive. Shanxin (a voice actress) has complained about the “particularly long recording table” of the voicebank (I didn’t find the original source, so I’ll put a [source request] here). In addition, because the same phonetic element uses repeated samples, the software cannot chang the timbre according to pitch, emotion, volume, and speed, which causes a bottleneck in realism of the voice.
Today the waveform concatenation method is being abandoned. Yamaha’s VOCALOID5 is the last generation of singing voice synthesis software that use this method.
Statistical model and vocoder
A vocoder (Vocodor) converts a speech signal into a series of parameters or converts the parameters back into a speech signal. In 1938, Homer Dudley at Bell Labs (there you go, Bell Labs again) invented the first vocoder device, which is capable of both encoding and synthesizing the human voice. Vocoders were initially used for encryption and bandwidth saving in communications transmissions and later in the production of electronic music.
The famous electronic band Daft Punk often uses vocoders to create “robotic” vocal effects in their songs.
The principle of the vocoder is the source-filter model of the human voice. The vocoder uses the STFT short time Fourier transform to slice the speech and obtain its frequency distribution.
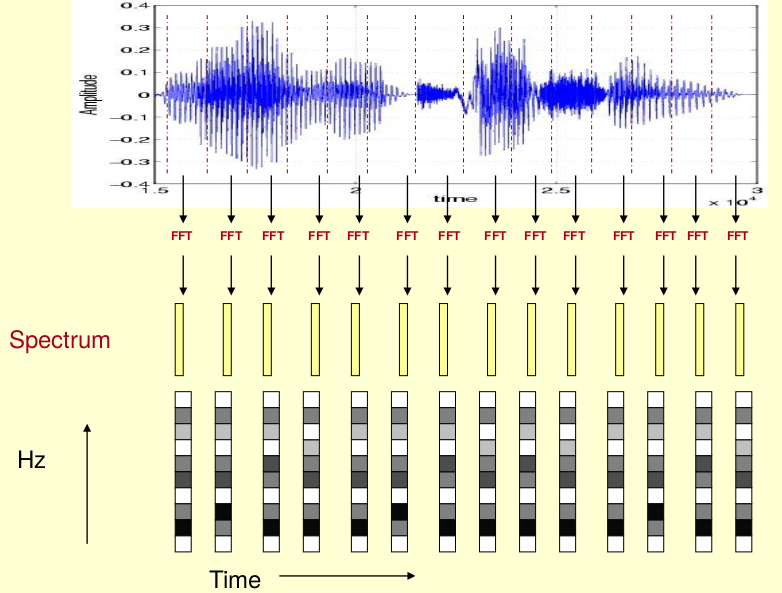
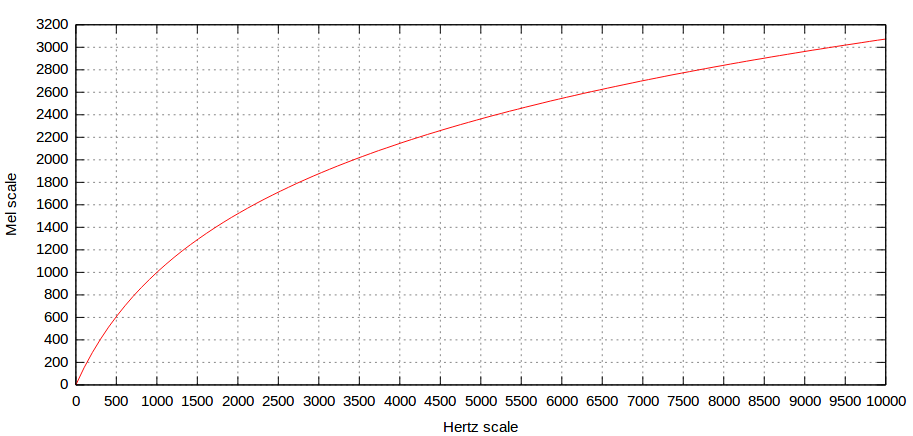
Since the sensitivity of the human ears to pitch is exponential rather than linear (100Hz to 200Hz is the same interval as 200Hz to 400Hz), we usually use Mel scale to measure frequency (i.e. Melody Scale). There is no strict definition of Mel scale. The common conversion formula is as follows:
$m = 2595 \log_{10}\left(1 + \frac{f}{700}\right)$
After converting to the frequency domain, the vocoder takes the Spectral Envelope, which is a smooth curve that connects the highest points on the spectra.
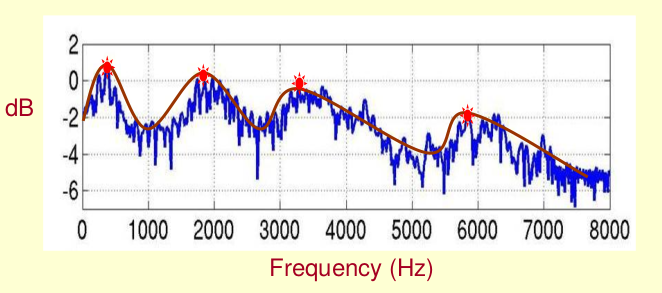
The spectral envelope curve is easy to find, and it only requires low-pass filtering of the spectral curve with frequency as the independent variable. It is equivalent to using low-pass filtering to filter out the fast-transforming noise.
In addition to finding the spectral envelope, vocoders often use Mel filter banks, Mel-scale Frequency Cepstral Coefficients (MFCC) and the DCT Discrete Cosine Transform (a simplified version of the DFT Discrete Fourier Transform) to find the multidimensional characteristics of the audio. In order to prevent the article from being too long, we will not go into details.
The spectral envelope describes the filter part of the source-filter model, which models the spectral parameters to synthesize the specified timbre and phoneme. The majority of modern Singing Voice synthesizers such as Synthesizer V and CeVIO are using this technique.

WORLD is an open source vocoder based on this algorithm, which we can use to implement a simple virtual singer script based on spectrum features.
WORLD vocoder divides sound characteristics into three parts: sound base frequency (F0), spectral envelop (sp) and aperiodicity (ap).
In the source-filter model, the F0 base frequency is the frequency of the impulse signal from the source, while the spectral envelope sp is the frequency response of the filter. The non-periodic ratio sp is the proportion of non-periodic signals in the voice. As mentioned before, the source can generate white noise in addition to periodic signals for unvoiced phonemes. The non-periodic signal share refers to the white noise share.
In the synthesis, the ap and sp parameters determine the timbre and phoneme of the voice. The WORLD vocoder has an open source python wrapper Pyworld.
This is a pitch-free sample from Luo Tianyi v4 Meng voicebank to derive ap/sp parameters containing timbral and phonetic features:
Next, we need to find a real human voice to extract the F0 fundamental frequency parameter.
The code I used was modified from the project demo of Pyworld:
from __future__ import division, print_function
import os
import soundfile as sf
import pyworld as pw
def main():
x, fs = sf.read('hearme/luogz1np.wav')
tx, tfs = sf.read('hearme/sxgz1.wav')#get f0
_f0, t = pw.harvest(x, fs)
f0 = pw.stonemask(x, _f0, t, fs)
sp = pw.cheaptrick(x, f0, t, fs)
ap = pw.d4c(x, f0, t, fs)
y = pw.synthesize(f0, sp, ap, fs, pw.default_frame_period)
sf.write('original_re_synth.wav', y, fs)
_f0_h, t_h = pw.harvest(tx, tfs)
f0_h = pw.stonemask(tx, _f0_h, t_h, tfs)
#frequencyScale=1.0594630**12
for i in range(0,len(f0_h)):
#f0_h[i]*=frequencyScale
if f0_h[i]>550.01:
f0_h[i]=f0_h[i-1]
y_h = pw.synthesize(f0_h, sp, ap, fs, pw.default_frame_period)
sf.write('combined.wav', y_h, fs)
print('Please check "test" directory for output files')
if __name__ == '__main__':
main()The synthesized vocals are below, which is pretty good.
Song synthesis based on mathematical modeling has gradually hit a bottleneck as well. The process of mathematical modeling makes many simplifications to the singing mechanism (e.g., treating the human body filter as a linear time-invariant system). As a result, the synthesized singing voice is not sufficiently detailed, and the sound quality is sometimes even inferior to that of the waveform concatenation.
Machine learning
As we all know, we live in an era where everything is machine learnable.
Singing voice synthesis is indeed a very suitable area for machine learning algorithms. The variability of spectral characteristics, pitch, and singing style in human singers makes it difficult to model directly with math. Machine learning algorithms are trained with human vocals to recognize their implied patterns and produce outputs similar to those of humans.
Machine learning score processing
The first step in synthesis is to read the score to get the F0 pitch curve of the song, the start position of the phoneme and the duration of the phoneme. While it is possible to obtain these information directly from the midi score, the real vocal is much more complex than the score. The singer sings with glissandos and transitions between notes, with vibrato on long notes, and with small fluctuations in pitch at the beginning and end of the note. The starting position of the phoneme is not synchronized with the score, but usually slightly advanced.
In traditional vocal synthesis software, the software generates a rough pitch line based on the midi score and relies on the user to do the fine tuning manually. Manual fine-tuning requires a high level of skill and has even given rise to specialized staff positions. Phoneme start positions are built into the synthesis algorithm, leaving little room for adjustment.
Machine learning to generate spectral parameters
Using machine learning to obtain the spectral (formants) parameters for vocoder use is more flexible and includes more details than traditional modeling analysis. For example, the difference in timbre of high and low tones, the difference in timbre of different singing styles, etc.
Here is an example of XiaoiceSing (an early version of the Xiaobing song synthesis framework) from Microsoft Research Asia. This is the architecture of the framework in its paper:
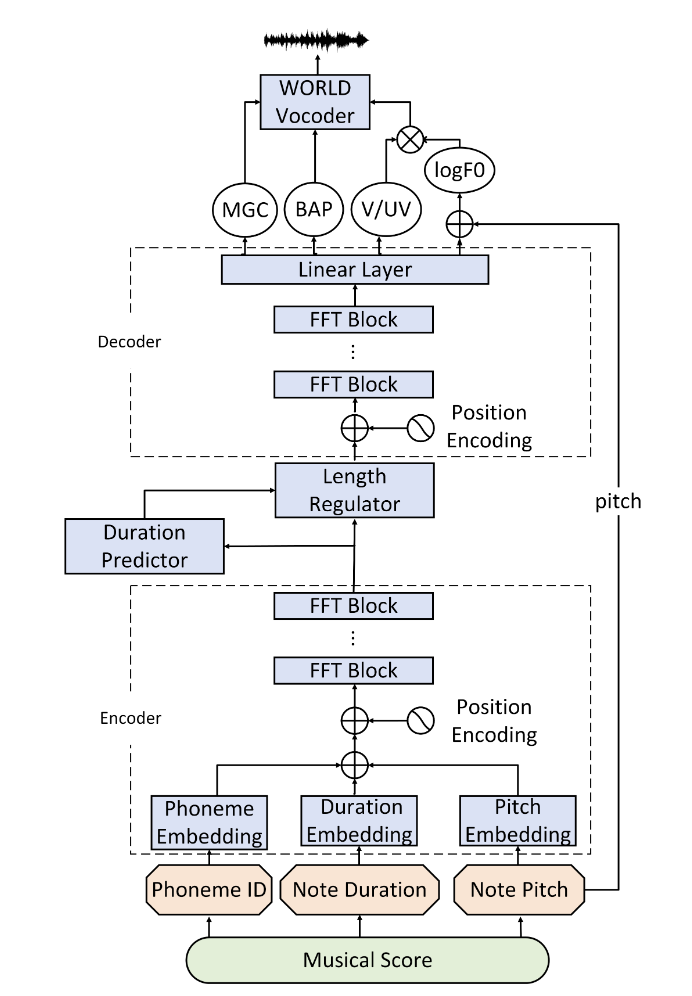
Speech
The score is first converted into vectors and then fed into the Encoder, which contains multiple FFT blocks. Each FFT block consists of a self-attention network and a two-layer 1-D convolution network with ReLU activation.

The output of the encoder is regularized by a note duration predictor composed of a one-dimensional CNN.
In the proposed system, WORLD vocoder is used to generate waveform, since it has explicit F0 control and can guarantee the correct expression of extremely high and low tones. Thus, the decoder will predict MGC(sp) and BAP(ap) features instead of mel-spectrogram.
Machine learning vocoder
The sound quality of XiaoiceSing-generated vocals is limited by its algorithm and vocoder. The traditional vocoder is becoming the bottleneck of the song synthesis system.
Machine learning-based vocoders generally use algorithms such as convolutional neural networks (CNN), generative adversarial networks (GAN) to generate waveforms. The representatives include Microsoft’s HifiSinger, Google’s Wavenet, etc. Here is an example of the architecture of RefineGAN, a GAN based vocodor:
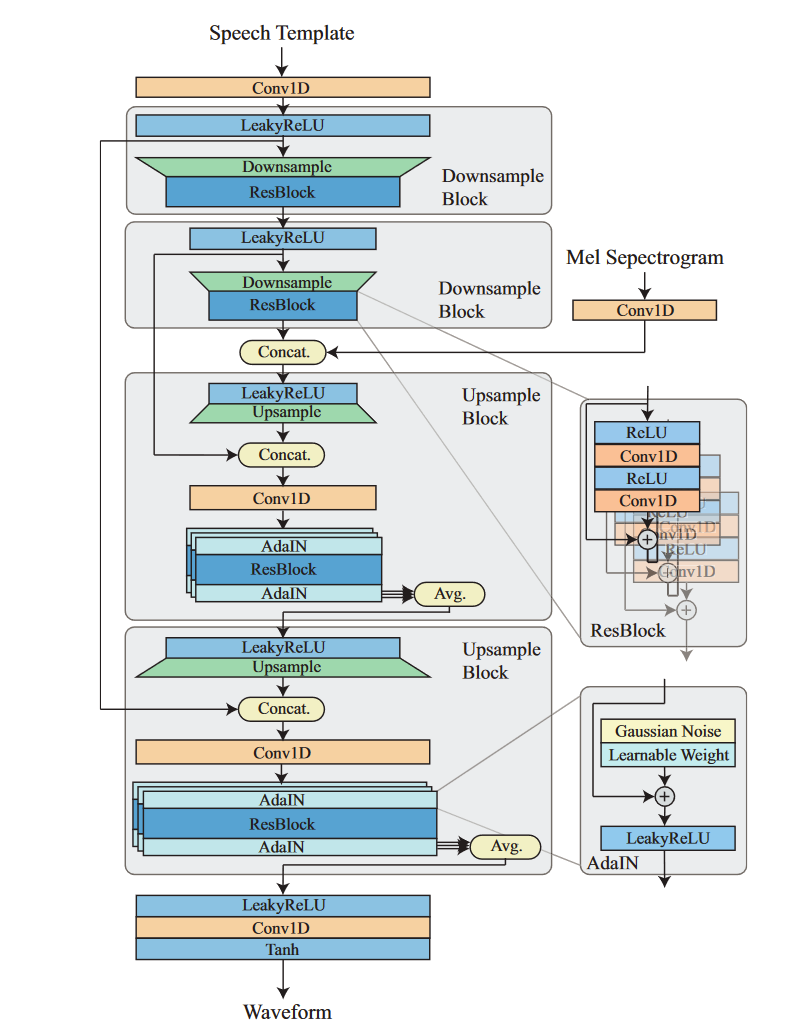
In the Mean opinion score (MOS) test, the sound quality of the synthesized audio from this vocoder even surpassed that of the ground truth (i.e., the real recorded audio).
The following is a demo of the vocals synthesized by this type of vocoder for the song “Flowing Light”.
Epilogue
“Principles of Song Synthesis” is the last section in the audio technology series, and also the longest section. At this point, the series is officially over.
More than sixty years ago, the engineers who had just made the IBM 7904 sing Daisy Bell probably didn’t expect the song synthesis technology to have such a big impact in the next century. Making computers sing doesn’t sounds to make much sense. After all, singing is supposed to be a human-to-human game, just like chess sports, art, and literature. Operating software to synthesize vocals is not only time-consuming, but the results are often inferior to those of real singers.
Then why do those people research the vocal synthesis technology?
Hard to answer. Maybe because the technology itself is so cool.

Maybe because of love.
Or maybe…
…”Because it’s there”.
References:
Chen, Jiawei et al. “HifiSinger: Towards High-fidelity Neural Singin Voice Synthesis.” Microsoft Research Asia. https://doi.org/10.48550/arXiv.2009.01776
Xu, Shengyuan et al. “RefineGAN: Universally Generating Waveform Better than Ground Truth
with Highly Accurate Pitch and Intensity Responses” timedomain. Inc https://doi.org/10.48550/arXiv.2111.00962
Wolfe, Joe et al. “An Experimentally Measured Source–Filter Model: Glottal Flow, Vocal Tract Gain and Output Sound from a Physical Model.” Acoustics Australia 44 (2016): 187-191.
Lu, Peiling et al. “XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System.” Microsoft Research Asia. https://doi.org/10.48550/arXiv.2006.06261
Human vocal communication of body size – Scientific Figure on ResearchGate. Available from: htPisanski, Katarzyna. (2014). Human vocal communication of body size.
WORLD vocodor https://github.com/mmorise/World
https://www.youtube.com/watch?v=RfPksLUblsM
https://zhuanlan.zhihu.com/p/388667328
https://zhuanlan.zhihu.com/p/499181697
https://sail.usc.edu/~lgoldste/General_Phonetics/Source_Filter_Demo/index.html