
我把灵魂分给她们一半,她们把歌声分给我一半。
——ilem
19世纪90年代初的某一天,英国作曲人Harry Dacre第一次踏上美国的土地。在入境美国的时候,他随身携带的自行车被收了一笔进口税。他的朋友William Jerome知道后调侃了一句:“幸亏你带的不是双人自行车,否则就要收双倍关税了”。“双人自行车”给了Dacre灵感,他于1892年初编写了一首名为《Daisy Bell》的歌曲,并于次年录制发行。
1961年,贝尔实验室的研究人员在使用IBM7094超级计算机研究语音合成时,决定尝试一下合成歌声。John Kelly和Carol Lockbaum负责了人声生成部分,Max Mathews负责了伴奏生成。他们选择了《Daisy Bell》这首当时已相当知名的爱情歌曲。《Daisy Bell》因此成为了世界上第一首由计算机合成人声演唱的歌曲。
本篇将讲解歌声合成原理和相关技术。
源-滤波器模型
1942年,千叶和梶山在其著作《The Vowel: Its nature and structure》(元音的性质与结构)中首次提出了一直沿用至今的源-滤波器模型(source-filter model)。源-滤波器模型认为人类发音系统由独立的两部分组成,其中声带作为源振动发声,发出的信号经过一个由声道、喉咙、口腔、鼻腔、牙齿与嘴唇构成的滤波器系统拥有了特定的频谱。

源决定了声音信号的频率。在讲话时,肺部挤出空气产生气流。当声带收缩闭合时,气流冲激冲击声带产生有规律振动,发出周期性的气流脉冲。声带发出的有规律脉冲为斜三角波,其时域和频域图像如下:

单个脉冲的数学表达式可近似为:
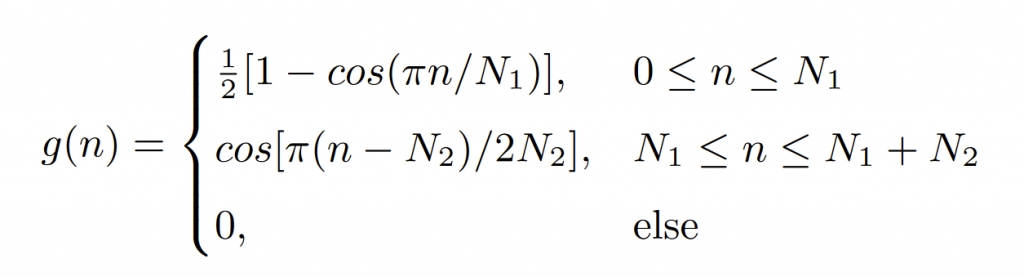
其中$N_1$为上升时间,$N_2$为下降时间。
脉冲的频率即为人声的基频。声带的发生的频率同时受声带的物理性质和紧张程度来控制。一般来说男性的基音频率为60-200Hz,女性和小孩为200-450Hz。基频决定了人说话的音高和唱歌的音域。当演唱音高超过音域时,声带会过度收缩产生高频振动。这种振动响度较小,需要依赖头腔共鸣放大,听起来比较尖、细,也就是所谓假声。
当声带放松时,高速流动的气流产生湍流,发出无规律的白噪音。
滤波器的性质决定了声音的频谱(spectrogram),频谱则决定的声音的音色和表达的内容。源发出的脉冲在经过滤波器系统后,其谐波会被不同程度的增强和减弱。频谱上谐波能量强的区域被称为共振峰。
2016年,新南威尔士大学的Joe Wolfe教授进行了一个实验来模拟源-滤波器模型。该实验使用了一个扬声器来模拟源,3D打印的共鸣腔来模拟人体来制造不同的语音。
其中“HAD”和“HEARD”所对应的共鸣腔形状不同,其对不同频率的透射率(transpedance)也不同,但都具有数个峰值(R1、R2、R3等)。源发出的脉冲在穿过共鸣腔滤波器后出现了数个频率峰值(F1、F2、F3等)。
以下为一些英语元音的频谱图,可以观察到每个元音都有其对应的共振峰:

这是一张发不同元音时的x光照片,红点代表舌位。舌位的不同使得人体共鸣腔的声学特性不同。

这些语音按一定节奏和频率规律发出,就有了歌声。理论上,只要知道每个音的频谱特征和基频,就可以通过逆变换得到波形。
这里说的公开信息,包括相关专利、相关论文和官方介绍等。
波形拼接法
大部分元音的频谱是固定不变的,但语言所包含的内容远不止元音。人在说话和歌唱时,每个字每个词都包含数个元音辅音。共振腔的形状随着声道形状、嘴唇开合、舌头位置不断变换,因此共鸣腔的频率响应也不断变换着,频谱是动态的,让语言信号处理变复杂了很多。
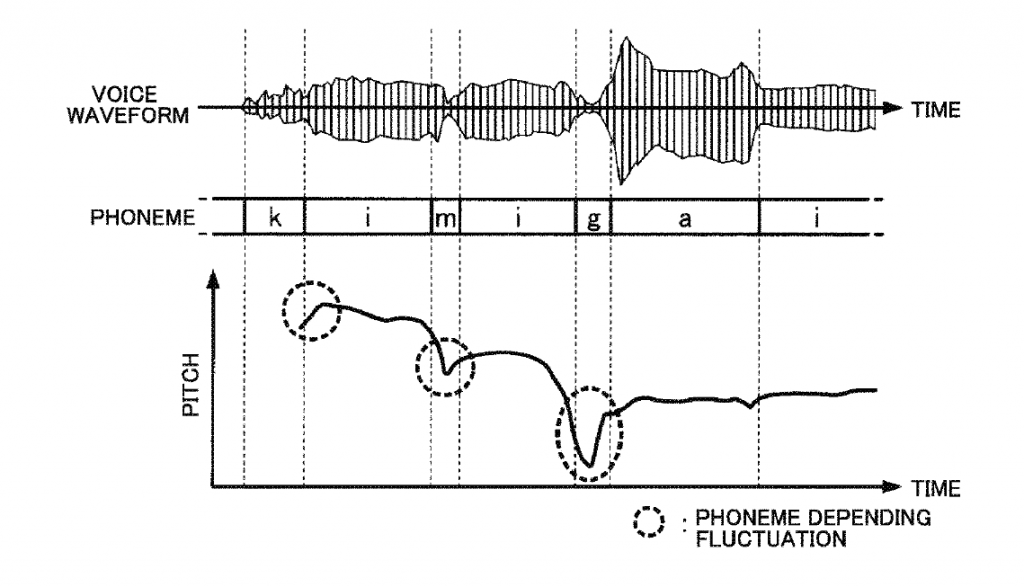
此外在真实的语音中,音素衔接位置处基频还会有微小的变动。这一现象在雅马哈的人声合成专利中被称为”Phoneme Depending Fluctuation”(音素依赖波动),如图。
考虑到这些因素,基于源-滤波器的人声合成需要复杂的算法和较高的处理器性能,否则听起来很假。因此早期合成软件纷纷采用了一种取巧的方案:波形拼接。
简单来说,波形拼接的语音合成提前录制好各种基本语素的采样,在使用的时候将波形升降调到需要的音高,再组成句子。
语音合成软件多数使用国际音标(International Phonetic Alphabet,IPA)来标记发音。原版IPA包含较多的特殊字符,为了方便计算机输入,常使用X-SAMPA等记法。
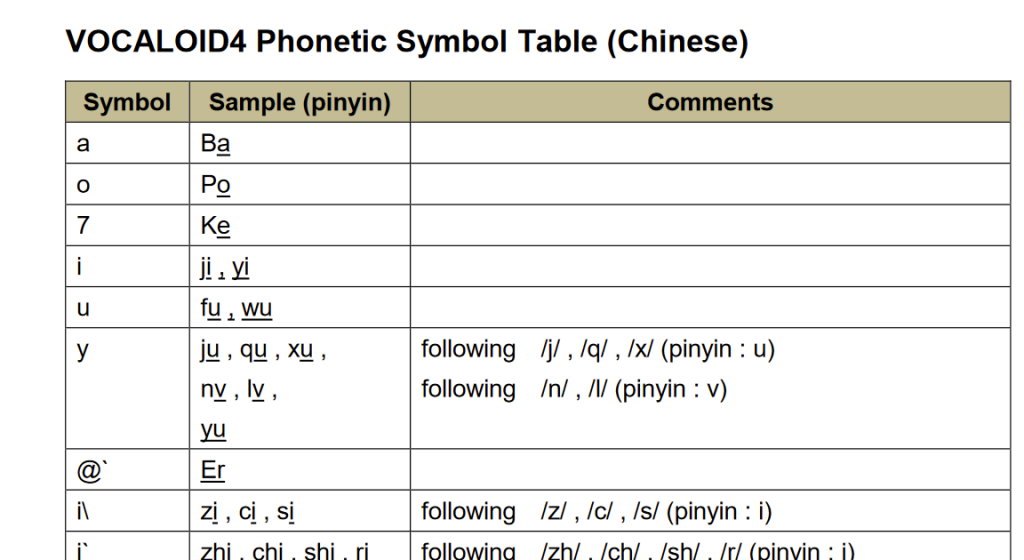
最知名的波形拼接语音合成软件可能是雅马哈的VOCALOID。以VOCALOID4为例,其.ddb声库文件中包含了一系列预先录制好的元音,辅音,以及音与音之间衔接的采样。

总采样数大约7600个。数量如此之多的原因是波形拼接算法很难处理好音与音之间的过渡,所以只能把所有过渡都枚举式的录制出来。下面有一些采样示例。例如IPA中的/a/,也就是现代汉语中的韵母a,以及/ən/到/i̯ou̯/(X-SAMPA中记为@_n和i@U)的衔接,即汉语拼音的en到you的衔接。
考虑到唱高音和唱低音时的音色变换,声库中每个音素都分三个音高录制了三份。
非常遗憾的是,由于声库用户使用协议的限制,这里不能展示任何采样示例。如果你实在好奇可以自己去听听看。
合成语音时,编辑器从声库中自动选择需要的音素拼在一起。这里以《勾指起誓》这首歌为例,查询VOCALOID用户手册第168页的拼音-音标表可以得知,”你是信的开头”的音素分别为n i s` i` s\ i_n t 7 k_h al @U。
找到对应的采样,把它们放到一起:
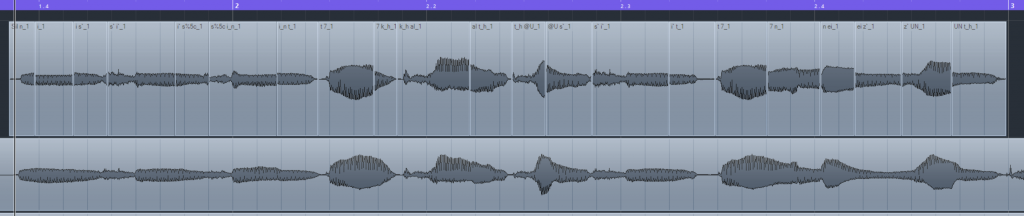
就能听到完整的句子了。手动拼接时的相位错位导致音频有少量爆音。
波形拼接法对音色保留较好,对性能要求低,但它的缺陷也很明显。波形拼接法在制作声库时需要录制大量(数千)的声音样本并进行人工标注,费时费力。山新本人曾吐槽过洛天依音源“录音表特别长”(没找到原话出处,所以先放一个【来源请求】)。此外,由于同音素使用的是重复的采样,音色不能根据音高、情感、音量、速度来变化,真实度存在瓶颈。
如今波形拼接法正在被逐渐弃用,雅马哈的VOCALOID5是最后一代使用此方法的歌声合成引擎。
统计模型与声码器法
声码器(Vocodor)可以将语音信号转换为一系列参数或将参数转换回语音信号。1938年,贝尔实验室(又是你们)的Homer Dudley发明了第一台能够解码和合成人声的声码器装置。声码器最初用于通信传输中的加密和节省带宽,后来也用于电子音乐的制作中。
著名电子乐队蠢朋克(Daft Punk)歌曲中的”机器人”人声就是用声码器制作的。
声码器的原理是人声的源-滤波器模型。声码器利用STFT短时傅里叶变换将语音分片,并取得其频率分布:
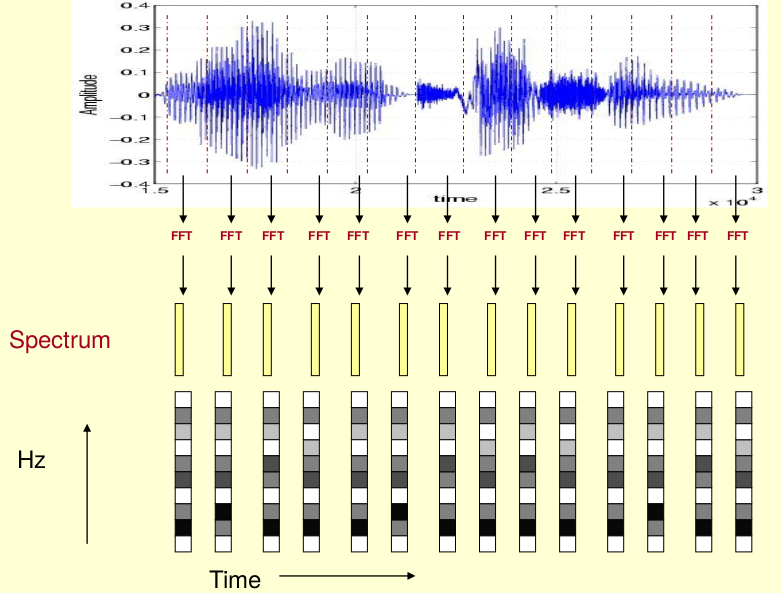
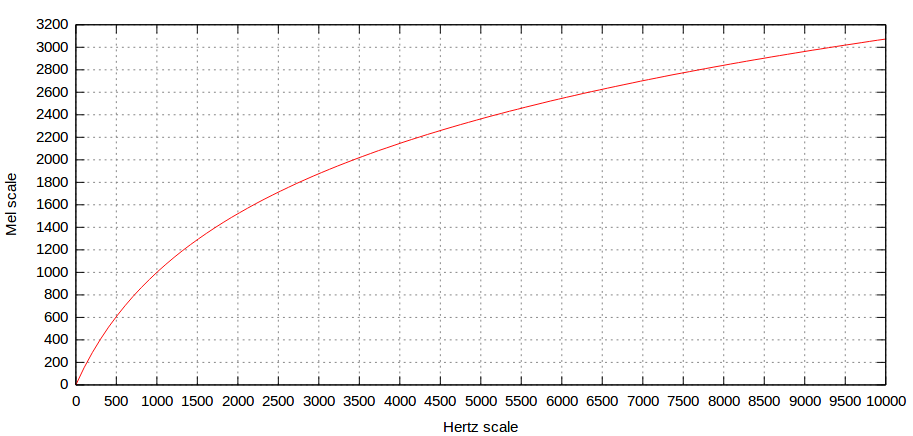
由于人耳对音高的敏感程度是指数的而不是线性的(100Hz到200Hz和200Hz到400Hz对人耳来说是一样的音程),频率一般会转换为梅尔标度(Mel scale,即Melody Scale)。梅尔标度并没有严格的定义,常用转换公式如下:
$m = 2595 \log_{10}\left(1 + \frac{f}{700}\right)$
在转换成频域后,声码器对其取频谱包络(Spectral Envelope),即将不同频率的振幅最高点连线以得到一条平滑曲线。
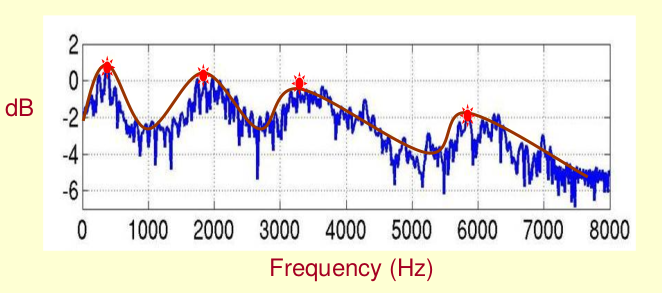
频谱包络曲线很好求,只需要对频谱曲线以频率为自变量做低通滤波即可。相当于利用低通滤波过滤掉快速变换的噪音,得到变换较慢的低频信号。
除了求频谱包络以外,声码器还常使用梅尔滤波器组、梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,MFCC)和DCT离散余弦变换(DFT离散傅里叶变换的简化版本)来求得音频的多维特征。为了防止文章过于冗长,就不细讲了。
频谱包络描述了源-滤波器模型的滤波器部分,对频谱参数建模即可合成指定的音色和语素。CeVIO和Synthesizer V等大部分现代语言合成引擎均采用此技术。

WORLD是一个基于传统算法的开源声码器,我们可以用它实现一个简单的基于特征提取的虚拟歌手引擎。
WORLD声码器将声音特征分为三部分:声音基频(F0),频谱包络(spectral envelop,sp)和非周期比值(aperiodicity,ap)。
在源-滤波器模型中,F0基频为源发出脉冲信号的频率,频谱包络sp为滤波器的频率响应。非周期比值sp则是语音中非周期信号的占比。前面提到过源除了能产生周期信号以外,还能产生白噪声来发气音。非周期信号占比指的就是白噪声占比。
在合成中,ap与sp参数决定了歌声的音色和语素。因此只要调整F0和音素时长,就能够合成指定音色的歌声。WORLD声码器有开源python封装Pyworld,下面这段代码修改自其项目demo。
这段代码通过给定F0,ap和sp参数来合成歌声。一般情况下,F0基频参数,也就是音高(即Vocaloid编辑器中的pit参数),需要根据乐谱和唱法绘制。这里偷了个懒,直接使用WORLD自带的harvest算法从提取人唱的歌声的F0。
在WORLD声码器中,F0如果为0,意味着当前发清音,源仅发出白噪声,不发出周期信号。
这是使用洛天依v4萌声库制作的无音高采样,用于提取包含音色和语素特征的ap/sp参数:
接下来需要找一个人声干音来提取F0基频参数。既然音色用的洛佬的,那最合适的干音自然来自是——洛佬她亲爹啦!诶嘿~
【山新】《勾指起誓》这里使用了utageo来消去伴奏获得人声。
合成用代码:
from __future__ import division, print_function
import os
import soundfile as sf
import pyworld as pw
def main():
x, fs = sf.read('hearme/luogz1np.wav')#音色的文件
tx, tfs = sf.read('hearme/sxgz1.wav')#提取f0的文件
_f0, t = pw.harvest(x, fs)#提取歌声的f0
f0 = pw.stonemask(x, _f0, t, fs)#原来音色的f0
sp = pw.cheaptrick(x, f0, t, fs)#原来音色的频谱
ap = pw.d4c(x, f0, t, fs)#原来音色的ap
y = pw.synthesize(f0, sp, ap, fs, pw.default_frame_period)
sf.write('original_re_synth.wav', y, fs)
_f0_h, t_h = pw.harvest(tx, tfs)#提取出的f0
f0_h = pw.stonemask(tx, _f0_h, t_h, tfs)#提取合成用的f0
#frequencyScale=1.0594630**12 #一个八度
for i in range(0,len(f0_h)):
#f0_h[i]*=frequencyScale #升调
#高音突刺处理
if f0_h[i]>550.01:
f0_h[i]=f0_h[i-1]
#换用t也就是tuned采样的
y_h = pw.synthesize(f0_h, sp, ap, fs, pw.default_frame_period)
sf.write('combined.wav', y_h, fs)
print('Please check "test" directory for output files')
if __name__ == '__main__':
main()
合成效果如下,可以说是相当不错了。(甚至比用VOCALOID编辑器做效果都好)
基于数学建模的歌声合成也逐渐遇到了瓶颈。数学建模的过程中对歌声机制做了很多简化(比如将人体的滤波器看做一个线性时不变系统),合成出的歌声细节不足,音质有时甚至不如波形拼接法。
机器学习时代
众所周知,现在是一个万物皆可机器学习的时代(划掉)。
歌声合成的确是一个很适用机器学习算法的领域。人类歌声中频谱特性、音调、唱法多变,很难直接用数学建模。机器学习算法使用人类的歌声进行训练,识别其隐含的模式,并产生和人类类似的输出。
机器学习乐谱处理
合成的第一步是阅读乐谱以获得歌声的F0音高曲线,音素开始位置和音素时长。这些信息虽然可以直接由midi乐谱得到,但真实歌声要比乐谱复杂的多。歌手演唱时音与音之间会有滑音、转音,唱长音时有颤音,音的开始和结束处存在音高的微小波动。音素的开始位置和乐谱不同步,一般会不同程度的稍微提前。
在传统歌声合成软件中,软件根据midi乐谱生成大致的音高线,微调依赖用户手动完成。微调需要用户专门学习和训练,门槛相对较高。音素开始位置则内置于合成算法中,调整空间不大。
机器学习生成频谱参数
利用机器学习来获得声码器使用的频谱(共振峰)参数,相比传统建模分析更灵活,包括更多细节,例如高低音的音色区别,不同唱法的音色区别,咬字方式的动态变化,等等。
下面以微软亚洲研究院的XiaoiceSing(小冰歌声合成框架的早期版本)为例,在其论文中,框架的架构图如下:
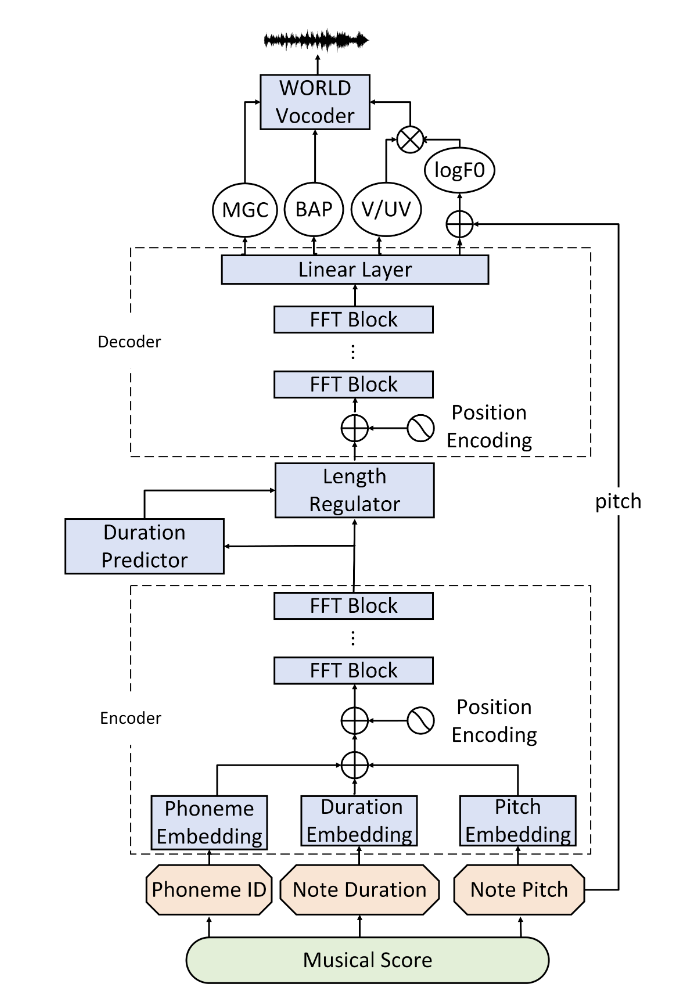
Speech
乐谱先转换成参数信息,再输入到由多个FFT块组成的编码器(Encoder)中。每个FFT块由一个Self-Attention Network(SAN)和一个带有ReLU激活的两层1-D卷积神经网络(CNN)组成。
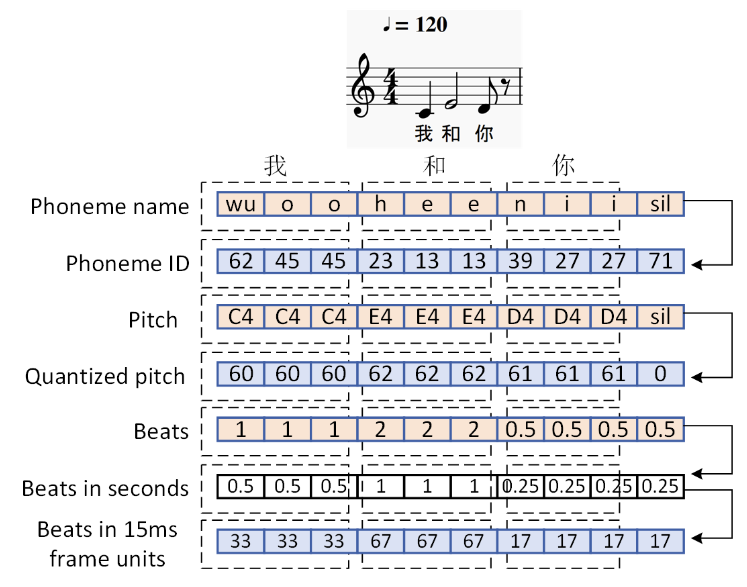
编码器的输出会被一个一维CNN组成的音符时长预测器规范化。
接下来,输出被送入由同样的FFT块构成的解码器(Decoder)以得到声音参数,即梅尔倒谱(mel-generalized cepstru,MGC)、非周期频段(band aperiodicit,BAP)、音高信息和清浊音(voiced/unvoiced,V/UV)标识。为了防止AI跑调,音高信息还要进行二次修正。
最后,XiaoiceSing将生成的参数输入WORLD声码器以合成波形。其中MGC即为我们熟悉的sp谱,BAP为ap谱,音高信息和清浊音标识结合得到F0参数。
机器学习声码器
XiaoiceSing由于算法自身不足和声码器的限制,所合成歌声的音质仍有提高空间。传统声码器正在逐步成为歌声合成系统的瓶颈。
基于机器学习的声码器一般使用卷积神经网络(CNN)、生成对抗网络(GAN)等算法生成波形。代表有微软的HifiSinger、谷歌的Wavenet等。这里以RefineGAN为例,以下为其项目架构图:
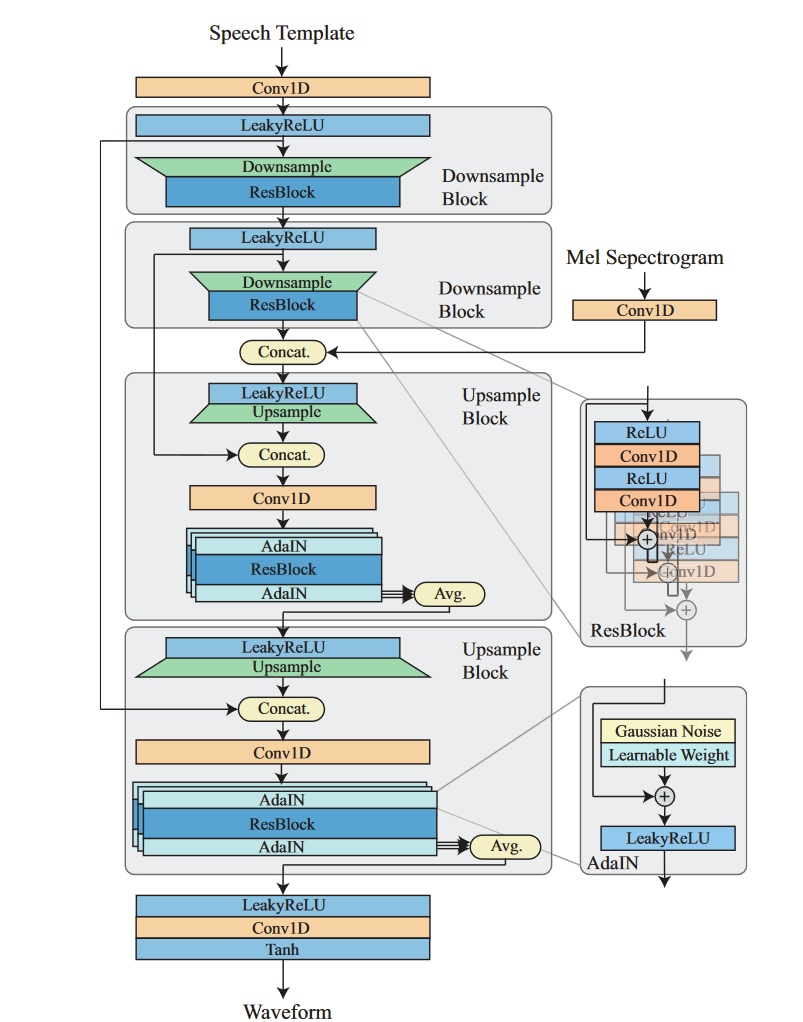
在平均主观分数(Mean opinion score,MOS)测试中,该声码器合成的音频音质甚至超过了地面实况(Ground truth,即真实录制的音频)。
下面为一段该类型声码器合成的人声试听,歌曲《流光记》:
结语
“歌声合成原理”是音频技术系列科普的最后一篇,也是耗时最长、字数最多的一篇。到此为止,本系列正式完结。
在六十多年以前,刚刚让IBM7904唱响Daisy Bell的工程师们大概没有料到,歌声合成技术会在下一个世纪产生如此之大的影响力。让计算机唱歌,乍一听没什么意义。毕竟唱歌本和棋类运动,艺术,文学一样,是人类与人类间的游戏。用软件合成歌声不仅麻烦,成品效果也常逊色于真实歌手。那为什么还要研究合成歌声?
因为技术这件事本身就很酷。

因为爱。

因为山就在那里(“Because It’s There”)。
参考文献
Chen, Jiawei et al. “HifiSinger: Towards High-fidelity Neural Singin Voice Synthesis.” Microsoft Research Asia. https://doi.org/10.48550/arXiv.2009.01776
Xu, Shengyuan et al. “RefineGAN: Universally Generating Waveform Better than Ground Truth
with Highly Accurate Pitch and Intensity Responses” timedomain. Inc https://doi.org/10.48550/arXiv.2111.00962
Wolfe, Joe et al. “An Experimentally Measured Source–Filter Model: Glottal Flow, Vocal Tract Gain and Output Sound from a Physical Model.” Acoustics Australia 44 (2016): 187-191.
Lu, Peiling et al. “XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System.” Microsoft Research Asia. https://doi.org/10.48550/arXiv.2006.06261
Human vocal communication of body size – Scientific Figure on ResearchGate. Available from: htPisanski, Katarzyna. (2014). Human vocal communication of body size.
WORLD vocodor https://github.com/mmorise/World
https://www.youtube.com/watch?v=RfPksLUblsM
https://zhuanlan.zhihu.com/p/388667328
https://zhuanlan.zhihu.com/p/499181697
https://sail.usc.edu/~lgoldste/General_Phonetics/Source_Filter_Demo/index.html
好耶,知识+1
好!
好耶
写的很好,加油!